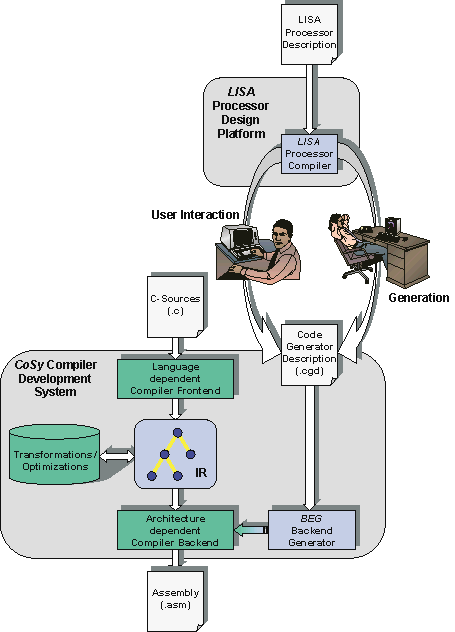
Although compiled simulation has the obvious benefit of a very high simulation performance,it also becomes apparent that certain requirements are put on architecture model and application, which significantly limit flexibility in terms of applicability. The basic idea of the JIT-CCS is to memorize the information extracted in the decoding (compilation) phase of an instruction for later re-use in case of repeated execution. Although the JIT-CCS combines the benefits of both compiled and interpretive simulation, it does not achieve the performance of statically scheduled simulations. Depending on architecture model and application, static scheduling techniques might require a complex program flow analysis involving consideration of more than one instruction at a time, which is unsuitable to (semi-)interpretive simulators. Therefore, the JIT-CCS exclusively incorporates dynamic scheduling for instruction decode/compilation. Since instruction decoding is performed on instruction register contents at simulator run-time, the usage of external memories is supported and program memory changes will be honored. Furthermore, the performance of compiled simulation can be approximated due to the caching of the decoded information. The additional overhead caused by migration of the decoding step into simulator run-time has proven to result in a negligible decrease of simulation speed. Moreover, the relative impact of the decoding process on simulation speed decreases strongly with increase of the number of loop iterations within an application.
The fact that the JIT-CCS operates on instruction registers instead of program memory gives a number of additional benefits, which are usually only provided by interpretive simulators Concerning flexibility, the choice of the resource from which the instruction word is loaded into the instruction register (instruction fetch) is entirely up to the model developer. This enables the modeling of e.g. memory management units (MMU) controlling whole memory hierarchies, or out-of-order dispatchers as found in superscalar architectures.
Furthermore, JIT-CCS allows scalable simulation, since size and replacement strategy of the simulation cache can be varied. Hence, simulation performance can be traded against host memory requirements and optimized for a specific architecture or even application. Generally, an effcient balance between those parameters would be achieved by a cache size capable of storing the entire body of the application's largest loop to avoid cache pollution.