
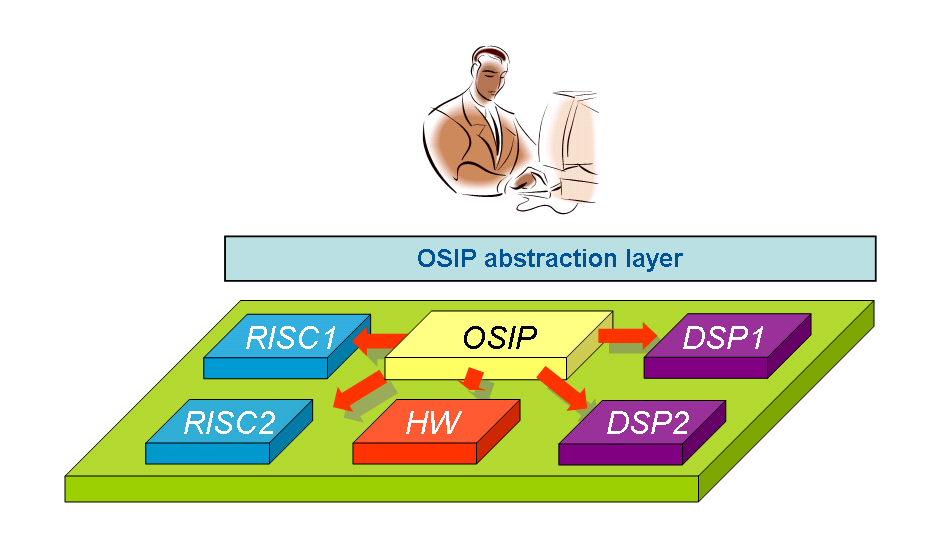
The OSIP Concept and Architecture
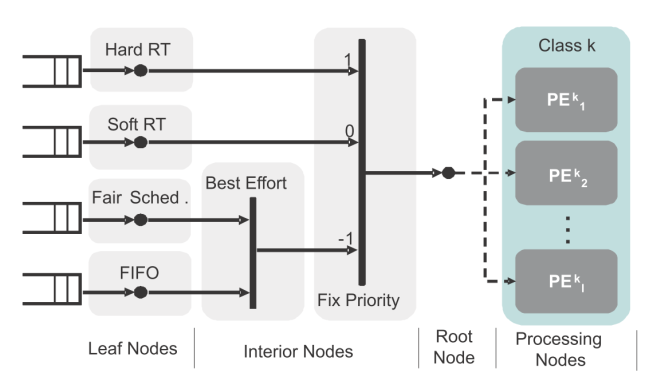
When designing OSIP, a flexible approach for task mapping, scheduling and synchronization was sought. This approach should be aware of the presence of several processors of different classes (e.g. RISC, DSP, ASIPs) and applications of different natures (e.g., hard/soft real time, best effort). To support all this, a hierarchical scheduling approach was selected as the OSIP underlying concept. The principle of hierarchical scheduling and mapping is illustrated in Figure 2. Leaf nodes represent task queues where individual tasks are scheduled according to local scheduling policies. Interior nodes implement schedulers and can be used to differentiate among the various application classes. From the root node, a task can be mapped to any processor in the corresponding class. Processing classes are user-defined and can be determined by physical architectural features (e.g. RISC, DSP, VLIW, HW accelerator) or by logical features (e.g. PEs sharing some cache level).
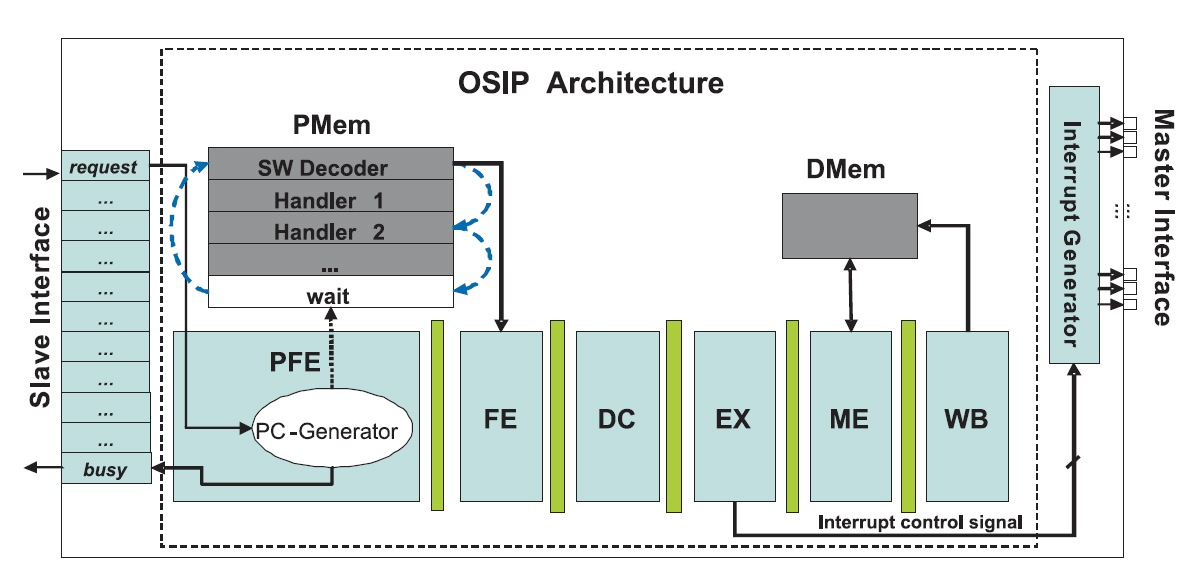
With an implementation of the scheduling behavior described above, OSIP was designed following a typical ASIP design flow with the Processor Designer tool from Synopsys. The resulting architecture, a 6 stage pipelined RISC, is shown in Figure 3. It includes a slave register interface to receive commands from the processors in the MPSoC. The master interface on the right hand side is used to trigger interrupts, which is the mechanism used by OSIP to schedule tasks on the processing elements. Several instructions were devised that accelerate the scheduling process. These includes, for example, instructions for traversing task queues and the scheduling hierarchy.
System Level View
OSIP can be easily integrated in an MPSoC by making the register interface visible from the processing elements and re-routing their interrupt signals. From the SW integration point of view, a lightweight abstraction layer composed of a set of Application Programming Interfaces (APIs) is provided. This APIs allow the programmer to write code independent of the platform and without necessarily knowing on which processing element the code would run.
A functional model based on SystemC was written for OSIP that allows faster system simulation. Both the functional model and the real ASIP were integrated in a virtual platform environment that includes up to 16 ARM926EJ-S processors, an AMBA AHB bus and several peripherals (see Figure 4). The virtual platform was modeled with Synopsys Platform Architect. This allowed to benchmark and to analyze the overhead incurred by scheduling with OSIP and compare it against pure SW solutions. The average overhead was of around 900 cycles, which is one order of magnitude smaller than typical SW Operating Systems.
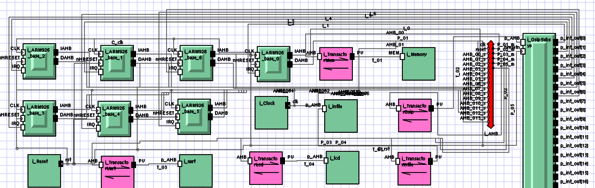
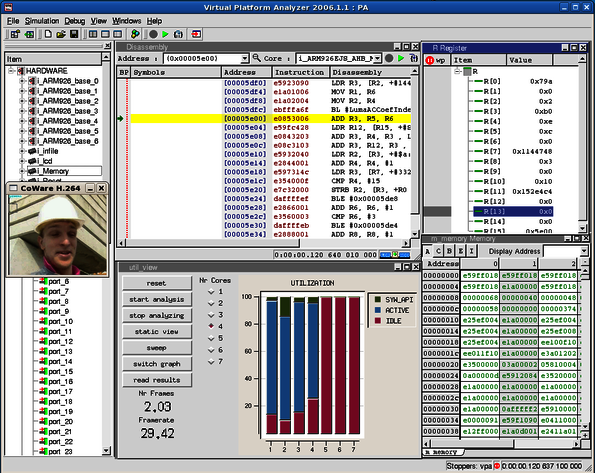
Figure 4 OSIP in Virtual Platforms. a) Virtual Platform. b) Virtual platform simulation for benchmarking
For more information about the OSIP technology please refer to the list of publications.
Current activities
- Analysis of communication architectures for OSIP based systems.
- Integration of OSIP into heterogeneous platforms.
- Integration of OSIP into the MAPS framework for MPSoC programming. This includes automatic code generation from dataflow languages to OSIP-based platforms.
Publications
Zhang, D., Zhang, H., Castrillon, J., Kempf, T., Ascheid, G. and Leupers, R.: Optimized Communication Architecture of MPSoCs with a Hardware Scheduler: A System View, in Proceedings of the International Symposium on System-on-Chip (SoC)(Tampere, Finland), pp. 163-168, Sep. 2010, ISBN: 978-1-42448-279-5
Castrillon, J., Zhang, D., Kempf, T., Vanthournout, B., Leupers, R. and Ascheid, G.: Task Management in MPSoCs: an ASIP Approach, in Proceedings of the 2009 IEEE/ACM International Conference on Computer-Aided Design (ICCAD '09)(San Jose, California, USA), pp. 587--594, Nov. 2009, ISBN: 978-1-60558-800-1