
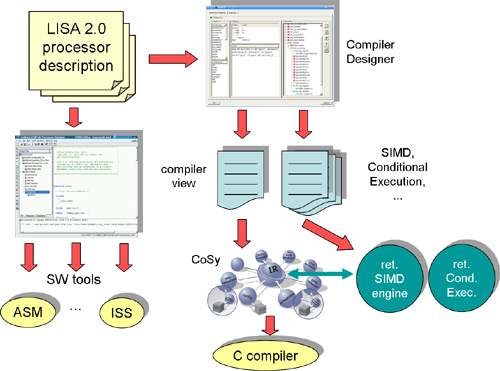

Project overview
All the development is done using the CoSy platform by the Netherlands based company ACE. There is a close research relationship with ACE, which includes student exchanges and regular meetings. The CoSy platform has been chosen because it provides a powerful and extensible framework to build compilers. This allows us to focus on the actual optimization, while resting assured that the remainder of the compiler is up to the latest standards.
The CoSy frameworks consists of several modules called engines. The optimizations are implemented as a set of additional engines. They can then be adapted to a specific processor instance by using configuration files that describe the specifics of a certain processor.
The following paragraphs offer more detailed descriptions of selected sub-projects that are part of this project.
SIMD optimization
Many embedded processors feature a set of multimedia extensions known as SIMD. These interpret a single register as a short vector of a smaller data-type. Common setups allow the use of 32 Bit registers for two 16 Bit or for four 8 Bit values. A single arithmetic operation, like an addition or multiplication, can then be executed for all vector elements in a single step.
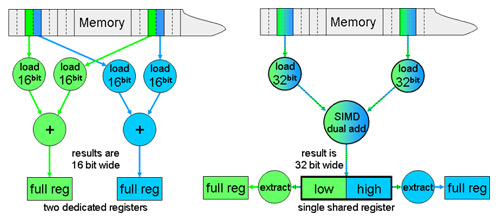
A retargetable approach to SIMD optimization has been explored and integrated into the CoSy framework. Retargetability is achieved by reusing CoSy's code selection capabilities.
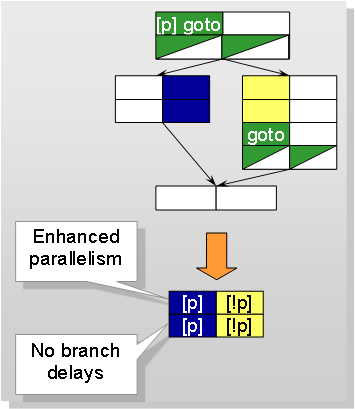
When used on VLIW processors the advantage is even more evident. In addition to the elimination of br/anch delays, basic blocks can be merged. This leaves more freedom to the scheduler and therefore enables more instructions to be executed in parallel. However this effect decreases with increasing size of the basic block. From a certain size onwards, there may be no noticeable effect or even an decrease in efficiency. It is therefore necessary, to decide on a case-by-case basis, whether the use of conditional instructions is profitable.
Conditional execution
Many processors, especially in the VLIW class, support conditional execution: an instruction is only evaluated if a Boolean condition, which is usually stored in a register, is met. If the condition is not met, the instruction behaves like a NOP. This feature is especially important on pipelined architectures, since it can be used to reduce jump operations in the code. Since jumps incur pipeline stalls, this often results in improved runtime behavior.
Publications
Hohenauer, M., Engel, F., Leupers, R., Ascheid, G. and Meyr, H.: A SIMD Optimization Framework for Retargetable Compilers, 2009
Hohenauer, M., Engel, F., Leupers, R., Ascheid, G., Meyr, H., Bette, G. and Singh, B.: Retargetable Code Optimization for Predicated Execution, in DATE(Munich, Germany), in DATE(Munich, Germany), Mar. 2008
Hohenauer, M., Schumacher, C., Leupers, R., Ascheid, G., Meyr, H. and van Someren, H.: Retargetable Code Optimization with SIMD Instructions, in CODES+ISSS(Seoul, Korea), in CODES+ISSS(Seoul, Korea), Oct. 2006