
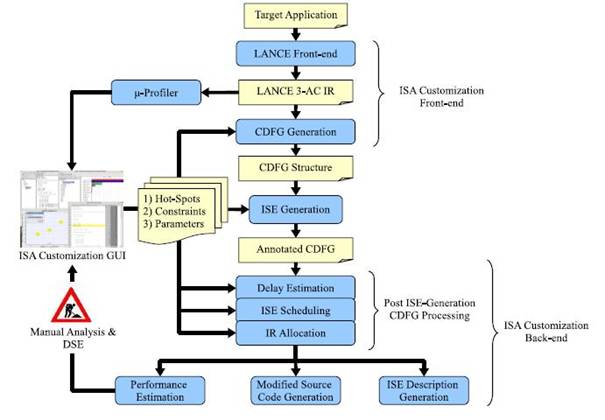
ISE Design-Flow
The proposed ISE design-flow is composed of three major parts: a frontend, ISE generation core algorithm and a backend. An advanced application C code analysis/profiling frontend is first using the LANCE compiler to generate the three-address code and as a second step, out of this code a Control Data Flow Graph (CDFG). The CDFG generation process creates a single node for the operation contained in an IR statement after recursively creating DFG nodes for all its constituent operands. Possibly, the designer can use the µ-profiler to locate the hot-sport of the application, by whose acceleration in HW the execution speed would benefit most. This portion of the code is then also represented as a graph. The generated graph is to be used in the core ISE generation algorithm. The problem of locating the custom instructions is reduced to the mathematical problem of constrained search in the data flow graph. There is a set of rules any newly selected custom instruction has to comply to. Those include data-flow constraints, like a guarantee of schedulability of the new code, or prevention of cyclic dependencies between instructions, then latency and area constraints (e.g. new instruction should fit in one clock cycle) and architectural constraints (taking into account the number of available general purpose registers, main memory access forbidden etc.). The problem of the limited number of GP registers is the most striking one, so there has been a proposal to use internal registers, visible only inside the extension fabric. They do not affect port area of the initial register file and allow a larger number of inputs and outputs to the custom instructions. The search through the graph can now be solved using an Integer Linear Program, where the indicator variable corresponds to the presence of the original instruction in the new custom one. The objective function to be maximized is the benefit of a function, computed as the speed-up it would bring to the application execution, reduced for the communication overhead that appears in case of using the internal registers. The second step of the ISE generation algorithm is another ILP for the edge assignment. It orders all the graph edges in the GP registers or internal registers, such to minimize the data coping overhead. Finally, the ISE synthesis backend receives an ISE annotated DFG and translates it into real-life processor models. It is built in two parts. The first part applies a set of generic transformations on the DFG to produce an executable sequence of base processor instructions and custom instructions, while the second part encapsulates most of the architecture specific details. Currently, the backend is capable of generating ISE descriptions for three cutting edge processor customization frameworks. These frameworks include two configurable processor based design flows (MIPS CoreXtend and ARC configurable cores) and one ADL based design flow (LISATek). Typically, three different sets of files are generated by the framework:
- Modified source code of the target application in ANSI C where the ISEs are inserted using calls to assembly functions.
- Definition of the assembly function for each ISE. The definitions of all the ISEs are generated in a separate header file which is included from the modified source code.
- Behavior of the ISEs in an RTL like format. This is primarily required for ISE implementation. The ISE behavior can be directly used for ISS or RTL generation, or can be hand optimized for final ASIP implementation.
Publications
Leupers, R., Karuri, K., Kraemer, S. and Pandey, M.: A Design Flow for Configurable Embedded Processors based on Optimized Instruction Set Extension Synthesis, in Design, Automation & Test in Europe (DATE)(Munich, Germany), Mar. 2006