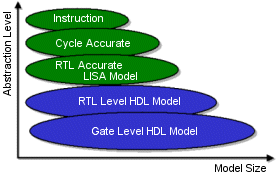
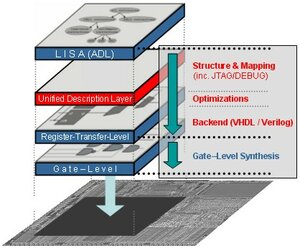
The key motivation behind embedding high-level optimization techniques in ADL-driven automatic RTL generation is the availability of information about semantical relations and mutual exclusive execution which can hardly be extracted from an RTL representation. The most important optimization techniques are shortly described in the following:
Decision Minimization: Decision Minimization utilizes semantical information in order to move condition-independent code out of the surrounding conditions. This optimizations reduces multiplexer instantiations and improves the timing significantly.
Signal Scope Localization: In LISA, it is possible to declare and use a signal resources globally in the model. During Signal Scope Localization, locality of the signal usage is explored and affected signals are converted into local resources.
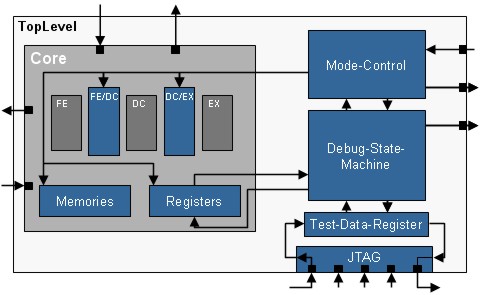
Decoder Distribution: Decoder Distribution is a structural optimization, where the instruction decoder is distributed over the entire pipeline. The decoded signals from earlier stage is fed into latter stage, in case it is used more than once.
Port Sharing: During the Port Sharing optimization, the exclusiveness relations of resource accesses are considered by mapping mutually exclusive accesses to shared ports.
Resource Sharing: Resource Sharing is performed using the exclusiveness information and cost models for chip area and signal delays. Based on this information, the cost models and constraints set by the designer, the sharing algorithm selects the sets of computational resources for sharing.
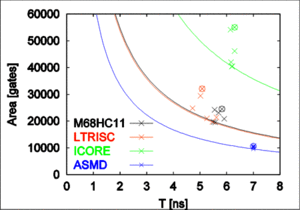
Using these optimization techniques, different points of the design space can be explored and tradeoffs between physical characteristics can be made.