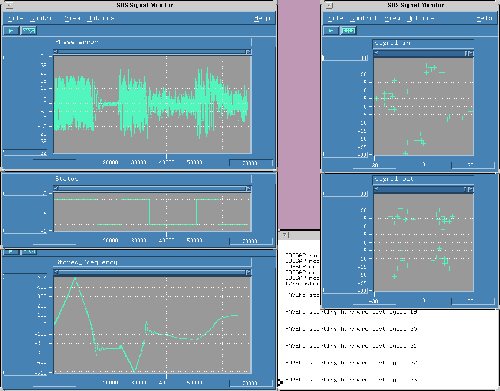
For the first 23000 samples, a constant negative frequency offset is applied to the samples within the channel at a high SNR (50 dB). After acquisition by sweeping first up then down, at 17000 the chip signalizes in-lock.
At about 20000 the channel is changed via 'sdsmsg' (a COSSAP tool for interactive control of simulation runs), which is visible after the next hardware test cycle (see below): now we apply a steadily increasing negative frequency offset (ramp) at an SNR of 13 dB. A new acquisition starts. At about 33000 the chip is in-lock again and follows now the frequency ramp.
At about 40000 we change via sdsmsg the parameters of some blocks that contain the values for the chip-configuration. This change is transmitted to the chip at the next hardware cycle with write direction (see below) which is at about 46000. In order to visualize the effect of the reconfiguration, we change the channel again (constant positive offset at SNR of 11 dB). The chip goes out of lock at 50000. Now you can see 1) the smaller slope (due to a reduced sweep value) and 2) the totally different transient behavior (due to changed loop parameters).
Overall simulation duration is 8min 30s on a SparcStation 20.
The hardware itself runs in bursts (so called hardware test cycles). We have to distinguish between two different kinds: 1) in shorter bursts (96 samples long) the chip is configured via the uP-interface, 2) in longer bursts (3840 samples long) phase error, status and stored frequency are read out via the uP-interface.
A total of 24 bursts is computed during the simulation.
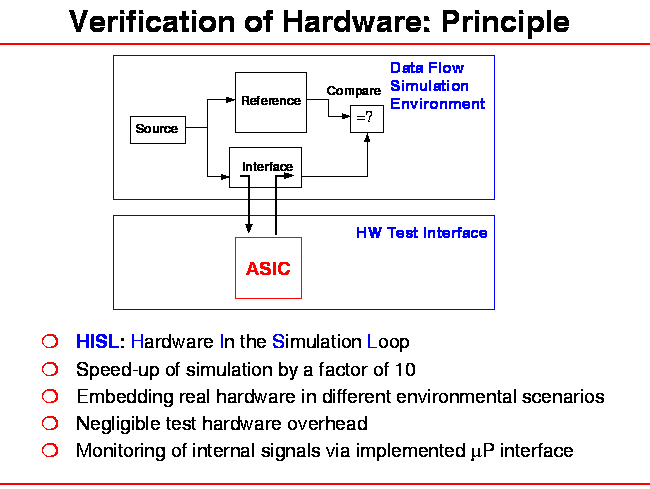
If the x-displays are switched of, overall simulation time is 80 sec, only. That means, when using the RAVEN technology in non-interactive mode, one gets a throughput, depending on the complexity of the COSSAP block diagram (and the workstation in use), of about 1000 samples/s. For the existing COSSAP-schematic, this is a speed-up by a factor of 10 compared to the bittrue and cycle-true SIMULATION of the DTVCAR-chip. However, this factor depends mainly on the ratio of complexity of the surrounding blocks (used for data generation and collection) and the amount of computation performed whithin the chip. When the complexity of the environment is decreased eg by means of generating the input samples in one non-hierarchical block, the speed-up between simulation and hardware should be more impressive. The same is true when embedding an ASIC with more functionality.
And now the picture for the marketing guys :-). In front of the RAVEN box, we see a wire-wrapped board with the device under test.