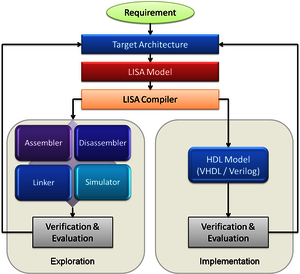
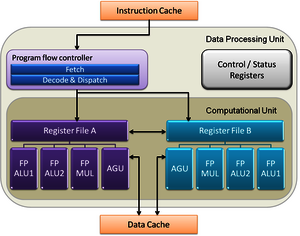
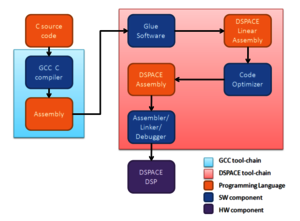
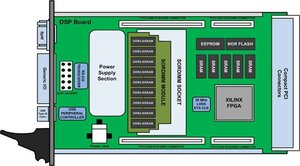
Donati, M., Saponara, S., Fanucci, L., Errico, W., Colonna, A., Tuccioc,, G., Odendahl, M.,
Leupers, R., Spada, A., Pii, V., Cordiviola, E., Nuzzolo, F. and Reiter, F.:
A New Space Digital Signal Processor Design,
in Lecture Notes on Electronic Engineering,
Springer,
Feb. 2014

Donati, M., Saponara, S., Fanucci, L., Errico, E., Colonna, A., Piscopiello, G., Odendahl, M.,
Leupers, R., Yakoushkin, S., Spada, A., Pii, V., Cordiviola, E., Nuzzolo, F. and Reiter, F.:
A new space Digital Signal Processor design,
in
APPLEPIES 2013 - International Conference on Electronic Applications,
Mar. 2013
Saponara, S., Fanucci, L., Donati, M., Odendahl, M.,
Leupers, R. and Errico, E.:
Next-generation digital signal processor for European space applications,
in SPIE Newsroom,
Mar. 2013,
10.1117/2.1201303.004719
Saponara, S., Donati, M., Fanucci, L., Odendahl, M.,
Leupers, R. and Errico, W.:
DSPACE hardware architecture for on-board real-time image/video processing in European space missions,
in
Real-Time Image and Video Processing Conference,
Feb. 2013
Odendahl, M., Yakoushkin, S.,
Leupers, R., Walter, E., Donati, M. and Fanucci, L.:
A Next Generation Digital Signal Processor for European Space Missions,
in
IEEE-AESS European Conference on Space and Satellite Telecommunications,
Oct. 2012 ©2012 IEEE
Colonna, A., Piscopiello, G., Errico, E., Tosi, P., Cordiviola, E., Bacci, B., Pii, V., Fanucci, L., Saponara, S., Donati, M., Vincenzi, A., Reiter, F., Nuzzolo, F.,
Leupers, R., Odendahl, M. and Yakoushkin, S.:
DSPACE: A New Space DSP Development,
in
Proceedings of The International Space System Engineering Conference,
May. 2012